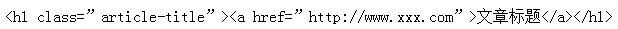H标签在SEO中至关重要,灵活的运用H标签代码有助于SEO,提升网站排名。H1、H2、H3等等这些标签以前只是HTML语言中最基本的一些标签,随着搜索引擎算法不断更新,这些标签被很多站长发现对SEO有很大的帮助,那么我们平时做SEO的时候应该如何利用好这些标签呢?
下面,秀站网就为您解析H1标签的作用及使用方法。
一、什么是H标签
H标签全称Heading标签,属于HTML编辑语言中对文本标题进行着重强调的一种标签。对于HTML本身还不是很了解的站长可以通过这篇文章了解一下:HTML是用来做什么的。
H标签从从H1-H6,代表着文字从大到小。依此显示重要性的递减,也就是权重依次降低。
二、H1标签在SEO中的作用
在设置H标签的时候,无论是首页、列表页还是内容页,H1标签只放一个,而H2标签依据内容多少不超过10个,H3标签一般就是边边角角的栏目名称这些,除H1标签外,H2、H3标签对SEO的作用并不大。
H1标签主要是用来向搜索引擎强调重要内容的一种标签,切记,任何情况下,一个页面只能存在一个H1标签。
三、H1标签的使用方法
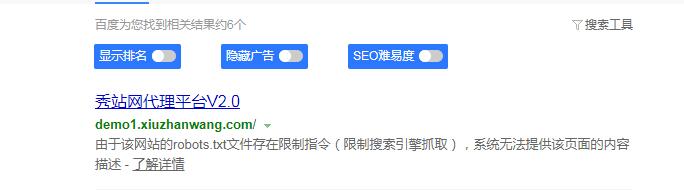
首页:首页的H1标签加在logo上,这样不仅能对主关键词起到强调效果,增强相关性,同时也不会影响美观。
具体写法:

参考样例:

内容页:内容页的H1标签要加在文章标题上,用来向搜索引擎强调文章标题(长尾关键词)。
具体写法: